

Partito alla fine di settembre (il 24/9/2025) su Kickstarter per raccogliere una cifra iniziale e vedere come poteva rispondere il
pubblico all'idea, il Firefly è un progetto che nasce dai microfoni
MEMS per svilupparsi e integrare la fisica acustica con l'elettronica e gli algoritmi di calcolo.
No, non ha cavalcato l'onda dell'AI. Non si pone quindi fra i tanti che all'AI fanno fare l'impossibile, spesso con risultati scadenti e abbonamenti da pagare. Loro hanno affrontato il
problema nella realtà fisica, nella matematica e l'hanno applicata al silicio, al metallo, alla plastica che avvolge il pezzo, assemblato con la colla, stampato in 3D e testato, maneggiato,
provato, ascoltato, fatto provare. Quello che ho tra le dita è un prototipo e adesso te lo racconto.
non è un articolo sponsorizzato
Ebbene sì, c'è gente anche on line che non fa le cose solo per un ricavo economico o per avere i click o i like. Grazie a Marc Mullens che ne aveva ricevuto uno per testarlo, sono entrato in contatto con i ragazzi della canadese Soundskrit. Non gli ho chiesto soldi e non ne ricaverò se tu ti comprerai o no questo prodotto. Mi limito a raccontartelo e colgo l'occasione per imparare un altro pezzo di scienza del suono e della ripresa microfonica. Mi hanno regalato un prototipo, hanno risposto a un sacco di domande e di fatto io sto testando come funziona, se funziona, gli mando feedback e loro ci lavorano. Sono un beta tester per il gusto di imparare.
Questo è un articolo in divenire perché i lavori sono in corso.

Una Startup canadese che si occupa di microfoni direzionali è nata nel 2019 nel comparto microfoni miniaturizzati MEMS, gli stessi micro microfoni che trovi installati su tutti gli SmartCosi in giro per casa in grado di sentirti a distanza, registrare le tue conversazioni, spiarti e dare lavoro a qualche impiegato che non capisce la tua lingua ma sente che ti diverti e lo aggiunge al codice di Alexa.
Ma gli SmartCosi hanno funzioni multiple, dalle telefonate (obsolete) alla registrazione di chat vocali, alla ripresa audio-video in altissima qualità.
Che il video sugli SmartCosi sia di altissima qualità lo abbiamo capito dai millemila spot delle case costruttrici che ci girano film e videoclip. Ma l'audio, per quanto di buona qualità, sugli SmartCosi è sempre abbastanza povero e si ricorre a kit esterni per ottenere un suono professionalmente accettabile.
L'innovazione della Soundskrit sta nell'aver modernizzato i microfoni MEMS con una evoluzione del prodotto. I microfoni miniaturizzati infatti sono
omnidirezionali e attraverso (array) insiemi di microfoni arrangiati in vari modi, si tenta di ottenere direzionalità
grazie a somme e sottrazioni acustiche da complicati calcoli matematici. Beamforming, una tecnica che si usa in molto ambiti per indirizzare flussi altrimenti dispersi, come le
onde radio, i segnali radar, sonar e quindi anche sonori. Il beamforming acustico.
La direzionalità della ripresa è necessaria ad isolare l'oggetto interessato alla registrazione sonora dal rumore circostante. Abbiamo già esempi di tecnologia con lo stesso scopo: microfoni
cardioidi o ipercardioidi, microfoni a tubo di interferenza come il celebre MKH416 ad esempio che ha la capacità
di ridurre ogni suono fuori dalla ripresa facendo sentire bene ciò che sta davanti alla capsula. Ottiene il risultato grazie al tubo di interferenza.
Giocare con segnali, fasi e ritardi dei flussi di segnali è la chiave di lettura per comprendere il Firefly.
Per gioco o per lavoro - a chi è dedicato il Firefly

L'intenzione forse è di creare un prodotto per una fascia di mercato precisa, i content creator che pubblicano storie interessanti solo con gli SmartCosi e poca roba attaccata. Un prodotto di largo consumo che magari è l'inizio di una avventura che apre anche al mercato dei microfoni Prosumer che attualmente è pieno sfondato di fornitori di prodotti, più o meno tutti basati sullo stesso progetto.
Ma il confine tra professionale e hobbistico si è molto assottigliato in tutti i settori e in ambiti professionali si usano prodotti prosumer nei normali flussi di lavoro. Tutto dipende da quanto sarà accettabile o buono il risultato.
Ma adesso passiamo alle questioni tecniche, che non sono di poco conto.
Firefly è un Dongle USB C molto semplice che a livello hardware (limite firmware momentaneo), offre un audio 48K/24 bit su due canali, Plug and Play/Compliant.
I controlli sono fisici per le 5 funzioni: volume alto e basso, mono cardioide frontale o di spalle, figura 8, stereo.
Il prototipo è semplicissimo, per questo anche pratico ed economico.
Si presta ad evoluzioni per essere portato su piani differenti e professionali perché se è vero che adesso è su un bus USB con un campionamento fisso, nulla vieta che se ne
possa derivare un microfono più sofisticato.
Ci sono comunque molti limiti che lo definiscono.
gli ingredienti - apriamolo e analizziamolo

Il cervello del device è un chip della cinese Espressif
Systems, un SoC (System on a
Chip) che integra al suo interno un processore dual core XTENSA LX7 della Cadence Tensilica, RISC a 32 bit per SoC.
Ti riporto una tabella tecnica di cosa può fare il chip, solo per farti capire a cosa è indirizzato. Molte di queste funzioni non sono attive, come il Wi-Fi o il BT:
⚡ ESP32-S3 in breve
-
Processore: Dual-core Xtensa LX7 @ fino a 240 MHz.
-
Memoria:
-
SRAM interna fino a 512 KB
-
Supporto a flash esterna (QSPI/Octal SPI, fino a 16 MB)
-
PSRAM opzionale fino a 8–16 MB.
-
-
Connettività:
-
Wi-Fi 2.4 GHz (802.11 b/g/n)
-
Bluetooth 5.0 (LE, Mesh, Long Range).
-
-
I/O:
-
AI e DSP:
-
Estensioni vector instructions per machine learning leggero (reti neurali, riconoscimento vocale, elaborazione immagini).
-
Pensato per applicazioni edge AI.
-
-
Security:
-
Secure boot, crittografia flash, AES, SHA, RSA, HMAC.
-
-
Consumi: Modalità ultra-low-power con coprocessore ULP ottimizzato.

Di questo SoC alla Soundskrit utilizzano solo alcune componenti e possono scrivere un firmware che ne piloti le funzioni, come gestire i ritardi dei suoni da ogni singolo microfono per indirizzare il flusso delle 6 riprese audio e fornire una migliore precisione nel determinare cosa ascoltare e cosa escludere dal raggio d'ascolto.
Il chip ESP32-S3 può memorizzare istruzioni, ricevere i dati digitali dai microfoni per trasformarli nel flusso PCM audio a 48 o 96K fino a 24 bit, pronto per
essere inviato in USB dopo aver sommato ed elaborato i segnali.
Il microfono inizia con il classico sistema a capsula, dove la pressione sonora crea un segnale elettrico analogico. La differenza è che questo segnale viene immediatamente convertito in digitale all'interno del microfono stesso, non da una scheda audio esterna.
La conversione avviene campionando il segnale a una frequenza elevatissima (sull'ordine dei Megahertz) per creare un flusso di dati PDM: una sequenza di 1 e 0 la cui densità nel tempo rappresenta l'ampiezza dell'onda sonora.
Più 1 ci sono nell'intervallo di tempo, più è alta l'ampiezza. Più 0 e più è bassa.
Questo disegna una rappresentazione precisa del suono.
Questo flusso binario è facile da trasmettere e gestire in spazi piccoli.
La variazione della densità di 1 e 0 crea un'immagine digitale molto precisa della forma d'onda, che viene poi inviata al processore (SoC). Quest'ultimo la converte nel formato standard PCM per renderla compatibile con i sistemi audio tradizionali. La conversione in PCM si realizza nei limiti del SoC, che in questo caso riesce a fornire fino a 96k/24bit, ma nel prototipo Firefly è limitata a 48k/24bit, probabilmente per ragioni di compatibilità.
PDM (Pulse Density Modulation) e PCM (Pulse Code Modulation) sono due metodi diversi per codificare i dati audio, con PDM che utilizza un flusso di singoli bit ad alta frequenza per rappresentare un segnale, mentre PCM ne campiona l'ampiezza a intervalli regolari.
Il Compromesso Fondamentale: Fisica vs. Elaborazione
Per sua natura fisica, un trasduttore di dimensioni millimetriche, come quello di un microfono MEMS, non può eguagliare il dettaglio e la sensibilità di una capsula a diaframma largo di un microfono da studio. Un diaframma più piccolo cattura meno energia acustica, il che si traduce in un segnale più debole e un rumore di fondo intrinseco (self-noise) più elevato.
Per superare questo limite fisico, tecnologie come il Firefly non si affidano a una singola capsula, ma a un array di microfoni multipli. Questo introduce un nuovo paradigma: il suono finale non è più una cattura diretta, ma una ricostruzione computazionale. Sebbene questo approccio offra enormi vantaggi, introduce anche un nuovo tipo di compromesso: la qualità del suono dipende dalla perfezione degli algoritmi del processore (DSP) che gestiscono fasi e ritardi, rendendolo suscettibile ad artefatti digitali, specialmente sui suoni complessi come i transienti.
Due Filosofie a Confronto: Combinazione Analogica
vs. Beamforming Digitale
Per capire i limiti e i pregi del Firefly, è utile confrontare le due filosofie di progettazione:
-
Il Microfono da Studio Tradizionale (Metodo Analogico): Un microfono a condensatore con pattern variabili utilizza una capsula a doppio diaframma. La variazione del pattern (cardioide, omni, ecc.) si ottiene combinando elettricamente i segnali dei due diaframmi con diverse polarità e ampiezze. Il segnale che ne risulta è "puro": è il prodotto diretto di una grande e sensibilissima membrana, non è una ricostruzione digitale per compensare ritardi tra componenti fisicamente separati.
-
Il Firefly (Metodo Computazionale): Il problema del rumore di fondo elevato dei singoli microfoni MEMS viene risolto in modo brillante: si sommano i segnali dell'array di 6 microfoni. Poiché il segnale utile è coerente tra i microfoni mentre il rumore è casuale, la somma rafforza il primo e attenua il secondo, ottenendo un eccezionale rapporto segnale/rumore. Questo, tuttavia, richiede un'intensa elaborazione DSP per allineare temporalmente i 6 flussi audio. È questa elaborazione a creare i pattern polari e a permettere funzioni intelligenti.
Lo Strumento Giusto per il Lavoro Giusto

Questa natura computazionale del Firefly lo rende uno strumento straordinariamente potente, ma con un target preciso.
I vantaggi sono innegabili: l'isolamento della sorgente è superiore a quello di molti microfoni tradizionali, si possono implementare algoritmi di cancellazione del rumore in tempo reale e funzionalità AI perfette per podcast, streaming e content creator. La tecnologia Soundskrit, con i suoi microfoni a dipolo "fisico", fornisce un segnale di partenza già pulito, potenziando ulteriormente l'efficacia del beamforming.
Tuttavia, questa stessa natura lo rende meno adatto per la ripresa microfonica professionale, dove il "dettaglio" e la "trasparenza" sono tutto. In quel contesto, si cerca una cattura del suono il più diretta e non processata possibile, affidandosi alla qualità di una grande capsula e all'acustica della stanza. Il suono del Firefly, per quanto eccellente, è una ricostruzione digitale intelligente; il suono di un microfono da studio è una cattura fisica diretta. Sono due filosofie diverse, per due necessità diverse.
Un Jolly per il Professionista in Mobilità

Una volta che il software sarà maturo e il firmware implementato correttamente, non c'è motivo per cui questo piccolo gioiello non possa diventare uno strumento prezioso in occasioni particolari.
Per un professionista, trovarsi in luoghi remoti senza la propria attrezzatura e avere l'inaspettata necessità di inviare un file della voce di alta qualità sarà più facile. Il Firefly potrebbe diventare la soluzione perfetta per registrazioni di emergenza di qualità.
Il Tallone d'Achille del Prototipo: la Risposta ai Transienti
Allo stato attuale (28 settembre 2025), il prototipo presenta un artefatto che necessita di essere risolto. Il problema non emerge durante una conversazione pacata, ma si manifesta non appena si spinge la voce con dinamiche più articolate e veloci.
La causa sembra essere una difficoltà nella gestione dei gradienti di pressione rapidissimi, ovvero i transienti. Questo crea una sorta di "sfocamento" del suono, che viene percepito come una distorsione o una vibrazione fisica. Come nell'encoding video a basso bitrate si generano artefatti nelle scene in rapido movimento, qui sembra che il sistema fatichi a processare l'enorme e improvvisa quantità di informazioni di un transiente.
La mia ipotesi è che il problema sia risolvibile a livello di firmware, ottimizzando i tempi di sincronizzazione dei sei flussi di dati PDM. Questa anomalia è emersa solo durante test approfonditi, e ho già inviato un'analisi dettagliata al reparto tecnico di Soundskrit.
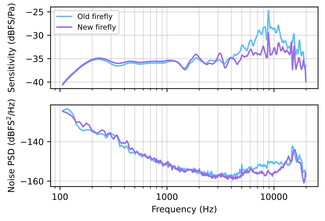
Il tempo di inviare una mail sabato sera e dopo poche ore ricevo una risposta da Stephen con un firmware aggiornato e una spiegazione circa la risposta in frequenza dai 4 ai 10K.

Questo è il file PCM 48/24 con il difetto riscontrato: https://ln5.sync.com/dl/b30abb3e0/7d4c9c5u-hsizc5hi-hsuacnf5-jdyvshz7
Gli avevo scritto alcune note:
Test su Dispositivi Mobili
Ho inizialmente testato il Firefly in sostituzione dei microfoni integrati di iPhone e iPad. Il miglioramento nella gestione del suono ambientale è immediatamente percepibile. La modalità stereo, in particolare, è affascinante.
Confronto in Studio vs. Neumann U87
Nella mia cabina di registrazione, ho confrontato il Firefly fianco a fianco con un Neumann U87, simulando una sessione di voice-over per uno spot pubblicitario. Ho identificato due specifiche caratteristiche audio:
1. Risonanza sui transienti rapidi
Registrando frasi a volume più alto, con livelli di pressione sonora (SPL) intorno a 95–100 dB (misurati alla posizione del microfono nel range 35 Hz > 8 kHz) — ma rimanendo comunque ben al di sotto del clipping (i livelli erano inferiori a –18 dBFS sulla DAW a 48 kHz/24 bit) — ho notato una sorta di vibrazione o risonanza. L'artefatto sembra essere innescato specificamente da transienti con un attacco molto rapido.
È importante notare che sono riuscito a riprodurre questo effetto anche a livelli di pressione sonora inferiori e a distanze maggiori, il che suggerisce che sia legato al tipo di suono piuttosto che al solo volume. Questo comportamento è identico su entrambi i lati in modalità cardioide.
Ho eseguito numerosi test per escludere problemi di natura meccanica (prove con e senza filtro anti-pop, a diverse distanze e livelli di guadagno, e persino con la scocca esterna rimossa). I risultati sono stati coerenti. La mia ipotesi è che possa trattarsi di un artefatto di beamforming, forse legato al modo in cui il processore gestisce la sincronizzazione nel dominio del tempo e della fase dei sei segnali microfonici durante i transienti rapidi. Le sembra una spiegazione plausibile?
Le invierò un link privato di YouTube che mostra uno dei test e allegherò anche il file audio della registrazione in formato PCM a 48/24.
2. Enfasi sulle alte frequenze
Ho inoltre osservato un notevole aumento tra i 4 kHz e i 10 kHz, che enfatizza marcatamente le consonanti sibilanti (“S” e “Z”).
arriva un nuovo Firmware
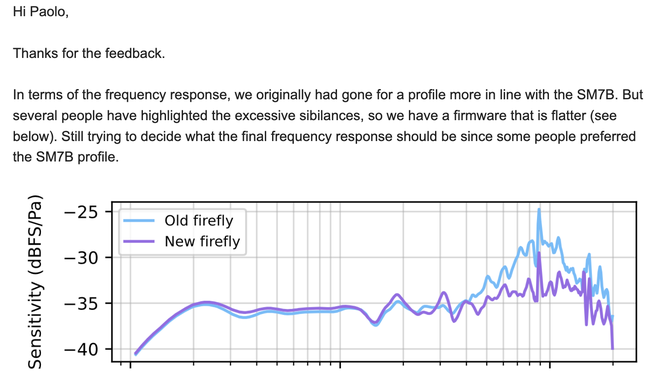
Non si sono limitati al nuovo firmware ma dato che stanno lavorando a modifiche hardware mi manderanno un nuovo prototipo che include le migliorie che hanno inserito. Quindi è un post in divenire quello che stai leggendo.
Continua nei prossimi giorni. Resta collegato.
Scrivi commento